Bug #11278
closed")
remove rb_control_frame_t::klass
Description
Abstract¶
rb_control_frame_t has a field klass, which is used to search super class when super is called (and also several usages). super is only for methods. However, all of rb_control_frame_t requires to keep klass on other frames such as block and so on.
This patch solve this issue by introducing rb_callable_method_entry_t.
https://github.com/ko1/ruby/tree/remove_cf_klass
rb_callable_method_entry_t is similar to rb_method_entry_t (actually, same data layout), but it has defined_class.
Background¶
For methods defined to classes, then owner of these methods are also defined_class.
class C1 < C0
def foo # foo's owner is C1, and foo's defined class is C0.
super
end
end
We can start to search super class from C1's super class (C0).
However, when we define methods in a modules, then defined class is not fixed.
module M
def foo # foo's owner is M, however, defined class is not fixed.
super
end
end
We can not search super class from module M.
M is used when some classes include (extend, prepend). These classes determine super classes.
class C1 < C0
include M
end
In this case, we can know super class of M#foo (included by C1) is C0.
To represent a correct class hierarchy, MRI uses special class T_ICLASS.
T_ICLASS is internal class points including (extending and prepending) modules like that:
C1 -> T_ICLASS -> C0
|
+-> M
# Let's use notation I(M) to represent this data structure.
# C1 -> I(M) -> C0
We can't determine defined class of M#foo, but we can determine a defined class I(M)#foo (in this case, it is C0).
Current MRI pushes defined class of methods onto control frame stack (rb_control_frame_t::klass).
However, it becomes overhead, especially for non-method frames such as blocks and so on.
To overcome this issue, I introduced rb_callable_method_entry_t,
which is similar to rb_method_entry_t, but has defined_class.
(rb_callable_method_entry_t is T_IMEMO/imemo_ment, same as rb_method_entry_t)
For C1#foo, the defined class is just C1. So rb_method_entry_t of C1#foo is also rb_callable_method_entry_t.
For M#foo, the defined class is not fixed. So rb_method_entry_t of M#foo is not a rb_callable_method_entry_t.
rb_callable_method_entry_t is created when M#foo is called by I(M).
We can find I(M) when we search M#foo in a class hierarchy C1 -> I(M) -> C0.
Let's call created rb_callable_method_entry_t for M#foo with I(M) as I(M)#foo.
It is inefficient that we make I(M)#foo everytime when M#foo is called.
So I(M)#foo is cached in a table pointed by I(M).
This table will be cleared when M is redefined.
pros. and cons.¶
Advantage:
- Faster pushing control frame especially for block invocation.
- Simplify codes around searching super classes.
Disadvantage:
- Increase memory consumption because of two reasons
- Duplicate method entries for methods defined by modules.
- Cache table kept by
I(M)
- Increase complexity maintaining method entries.
rb_method_entry_twas a simple enough data structure. We need to consider which data structures are required.
Measurement¶
For performance.¶
I do benchmark repeating 10 times (pickup the fastest results).
Speedup ratio: compare with the result of `trunk' (greater is better)
name modified
app_answer 1.032
app_aobench 0.989
app_erb 1.006
app_factorial 1.000
app_fib 1.026
app_lc_fizzbuzz 1.144
app_mandelbrot 1.032
app_pentomino 0.996
app_raise 0.996
app_strconcat 0.981
app_tak 0.999
app_tarai 1.004
app_uri 1.001
array_shift 0.913
hash_aref_flo 1.023
hash_aref_miss 1.097
hash_aref_str 1.074
hash_aref_sym 1.051
hash_aref_sym_long 1.047
hash_flatten 1.002
hash_ident_flo 1.020
hash_ident_num 1.038
hash_ident_obj 1.036
hash_ident_str 1.055
hash_ident_sym 1.016
hash_keys 0.993
hash_shift 1.046
hash_values 1.006
io_file_create 0.983
io_file_read 0.985
io_file_write 1.014
io_select 0.958
io_select2 0.972
io_select3 1.027
loop_for 1.067
loop_generator 0.980
loop_times 1.078
loop_whileloop 0.995
loop_whileloop2 1.005
marshal_dump_flo 1.014
marshal_dump_load_geniv 0.989
marshal_dump_load_time 0.988
securerandom 0.944
so_ackermann 1.018
so_array 1.049
so_binary_trees 0.993
so_concatenate 1.036
so_count_words 1.012
so_exception 0.989
so_fannkuch 1.017
so_fasta 1.003
so_k_nucleotide 1.005
so_lists 1.001
so_mandelbrot 0.998
so_matrix 0.987
so_meteor_contest 1.035
so_nbody 0.997
so_nested_loop 1.054
so_nsieve 1.010
so_nsieve_bits 1.022
so_object 0.992
so_partial_sums 1.018
so_pidigits 0.993
so_random 0.981
so_reverse_complement 0.986
so_sieve 1.007
so_spectralnorm 1.014
vm1_attr_ivar* 0.991
vm1_attr_ivar_set* 0.987
vm1_block* 1.009
vm1_const* 0.983
vm1_ensure* 0.960
vm1_float_simple* 0.954
vm1_gc_short_lived* 1.002
vm1_gc_short_with_complex_long* 1.004
vm1_gc_short_with_long* 0.996
vm1_gc_short_with_symbol* 0.998
vm1_gc_wb_ary* 1.004
vm1_gc_wb_ary_promoted* 1.141
vm1_gc_wb_obj* 0.998
vm1_gc_wb_obj_promoted* 0.963
vm1_ivar* 0.982
vm1_ivar_set* 1.010
vm1_length* 1.006
vm1_lvar_init* 0.938
vm1_lvar_set* 0.990
vm1_neq* 0.987
vm1_not* 1.013
vm1_rescue* 1.053
vm1_simplereturn* 1.030
vm1_swap* 1.017
vm1_yield* 1.032
vm2_array* 0.987
vm2_bigarray* 1.014
vm2_bighash* 0.987
vm2_case* 1.001
vm2_defined_method* 1.003
vm2_dstr* 0.997
vm2_eval* 0.982
vm2_method* 1.011
vm2_method_missing* 0.973
vm2_method_with_block* 1.027
vm2_mutex* 1.065
vm2_newlambda* 1.014
vm2_poly_method* 0.962
vm2_poly_method_ov* 0.972
vm2_proc* 1.058
vm2_raise1* 0.977
vm2_raise2* 0.990
vm2_regexp* 1.006
vm2_send* 1.005
vm2_struct_big_aref_hi* 1.005
vm2_struct_big_aref_lo* 1.010
vm2_struct_big_aset* 1.005
vm2_struct_small_aref* 1.030
vm2_struct_small_aset* 1.019
vm2_super* 0.900
vm2_unif1* 1.031
vm2_zsuper* 0.913
vm3_backtrace 1.004
vm3_clearmethodcache 0.937
vm3_gc 0.996
vm_thread_alive_check1 0.963
vm_thread_close 1.028
vm_thread_create_join 1.007
vm_thread_mutex1 1.047
vm_thread_mutex2 1.842
vm_thread_mutex3 1.028
vm_thread_pass 0.665
vm_thread_pass_flood 0.960
vm_thread_pipe 0.998
vm_thread_queue 0.995
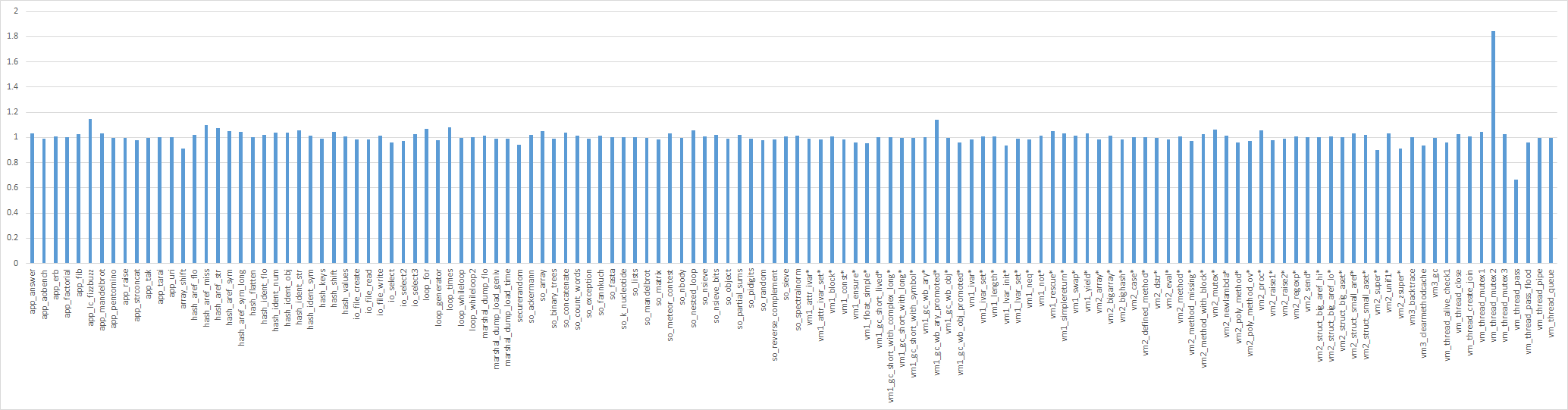
Not so big change. vm2_super/zsuper should improve performance so I need to check it again.
Memory consumption¶
Runing this script to check process memory on Linux Ubuntu.
N = 100_000
$mod = true
$cls = true
module M
N.times{|i|
define_method("foo#{i}"){}
} if $mod
end
class C
include M
N.times{|i|
define_method("bar#{i}"){}
} if $cls
end
class D
include M
N.times{|i|
define_method("bar#{i}"){}
} if $cls
end
class E
include M
N.times{|i|
define_method("bar#{i}"){}
} if $cls
end
[C, D, E].each{|c|
obj = c.new
N.times{|i|
obj.send "foo#{i}" if $mod
obj.send "bar#{i}" if $cls
}
}
puts File.readlines('/proc/self/status').grep(/VmHWM/)
This program makes 100_000 methods for a module and classes.
Maybe it is too big example.
Making methods on classes and a module.
ruby 2.2
VmHWM: 247624 kB
trunk
VmHWM: 234004 kB
modified
VmHWM: 252236 kB
Making methods only on a module.
ruby 2.2
VmHWM: 77848 kB
trunk
VmHWM: 86452 kB
modified
VmHWM: 108756 kB
Making methods only on classes.
ruby 2.2
VmHWM: 175780 kB
trunk
VmHWM: 182944 kB
modified
VmHWM: 179216 kB
As you can see, first result shows 2% increase for memory usage compare to Ruby 2.2.
Second result shows 40% increase, but it is worst case.
Third result is best case (no methods in modules).
We need to check real usage.
Future work¶
I will try class level cache proposed by funnyfalcon before, over there.
Files
") Updated by
Updated by ") Updated by
Updated by