Feature #18045
closed")
Variable Width Allocation Phase II
Description
GitHub PR: https://github.com/ruby/ruby/pull/4680 ¶
Feature description¶
Since merging the initial implementation in #17570, we've been working on improving the performance of the allocator (which was one of the major drawbacks in the initial implementation). We've chosen to return to using a freelist-based allocator and added support for variable slot size pages in what we call "size pools". We're still keeping the USE_RVARGC compile-time flag that maintains current behaviour when it is not explicitly enabled.
Summary¶
- We now use pages with different slot sizes in pools to speed up allocation. Objects will be allocated in the smallest slot size that fits the requested size. This brings us back to the freelist-based allocation algorithm and significantly increases allocation performance.
- The heap growth algorithm has been changed to adapt to the growth pattern of the size pool. Heaps that rapidly allocate and deallocate are considered "growth heaps" and are treated differently than heaps that are stable in size.
Size pools¶
In this patch, we introduce a new structure into the GC called "size pools". Each size pool contains an eden and tomb heap to hold the pages. The size pool determines the slot size of the pages in it. We've chosen powers of 2 multiples of RVALUE size as our slot sizes. In other words, since the RVALUE size is 40 bytes, size pool 0 will have pages with slot size 40B, 80B for size pool 1, 160B for size pool 2, 320B for size pool 3, etc. The reason we chose powers of 2 multiples of RVALUE is that powers of 2 are easy to work with (e.g. we can use bit shifts) and using multiples of RVALUE means that we do not waste space for the single RVALUE (40 byte) allocations. When VWA is not enabled, there is only one size pool.
Heap growth algorithm¶
This patch changes heap growth when USE_RVARGC is turned on. Heap growth is now calculated after sweeping (rather than after marking). This is because we don't know the characteristics of a size pool after marking (we only know the number of marked slots vs. total number of pages). By keeping track of the number of free slots and swept slots of each size pool during sweeping, we know the exact number of live vs. free slots in each size pool. This allows us to grow the size pool according to its growth characteristics. For example, classes are allocated in the third size pool (160B slot size). For most workloads, classes are allocated at boot and very rarely allocated afterwards. Through the data collected during sweeping, we can determine that this size pool is no longer growing and thus allow it to be very full.
Lazy sweeping¶
At every sweeping step, we attempt to sweep a little bit of every size pool. If the size pool we're allocating into didn't yield a page during sweeping and that size pool is not allowed to create new pages, then we must finish sweeping by sweeping all remaining pages in all other size pools. This may cause some lazy sweeping steps to take longer than others, we can see the result of this in the worse p99 response time in railsbench.
Benchmark setup¶
Benchmarking was done on a bare-metal Ubuntu machine on AWS. All benchmark results are using glibc by default, except when jemalloc is explicitly specified.
$ uname -a
Linux 5.8.0-1038-aws #40~20.04.1-Ubuntu SMP Thu Jun 17 13:25:28 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
glibc version:
$ ldd --version
ldd (Ubuntu GLIBC 2.31-0ubuntu9.2) 2.31
Copyright (C) 2020 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
jemalloc version:
$ apt list --installed | grep jemalloc
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
libjemalloc-dev/focal,now 5.2.1-1ubuntu1 amd64 [installed]
libjemalloc2/focal,now 5.2.1-1ubuntu1 amd64 [installed,automatic]
To measure memory usage over time, the mstat tool was used.
Master was benchmarked on commit 84fea8ee39249ff9e7a03c407e5d16ad93074f3e. The branch was rebased on top of the same commit.
Performance benchmarks of this branch without VWA turned on are included to make sure this patch does not introduce a performance regression compared to master.
Benchmark results¶
Summary¶
- We don't expect to see a significant performance improvement with this patch. In fact, our main goal of this patch is for Variable Width Allocation to have performance and memory usage comparable to master.
- railsbench:
- VWA uses about 1.02x more memory than master.
- When using jemalloc, VWA is about 1.027x faster than master.
- We see no (within margin of error) speedup when using glibc.
- In both glibc and jemalloc we see worse p99 response times described above in "Lazy sweeping" section. However, the p100 response times of VWA is comparable to master.
- rdoc generation:
- VWA uses 1.13x less memory than master.
- liquid benchmarks:
- We see no significant performance changes here.
- optcarrot benchmark:
- We see no significant performance changes here.
railsbench¶
For railsbench, we ran the railsbench benchmark. For both the performance and memory benchmarks, 50 runs were conducted for each combination (branch + glibc, master + glibc, branch + jemalloc, master + jemalloc).
glibc¶
For glibc, the RPS between the three are all within the margin of error. However, the p99 of the branch with VWA is significantly worse than master (3.2ms vs 1.8ms). This is due to the longer lazy sweeping steps discussed above. However, this isn't a problem for p100 response times.
+-----------+-----------------+------------------+--------+
| | Branch (VWA on) | Branch (VWA off) | Master |
+-----------+-----------------+------------------+--------+
| RPS | 731.69 | 724.19 | 727.02 |
| p50 (ms) | 1.33 | 1.38 | 1.37 |
| p66 (ms) | 1.37 | 1.41 | 1.40 |
| p75 (ms) | 1.38 | 1.42 | 1.41 |
| p80 (ms) | 1.39 | 1.43 | 1.42 |
| p90 (ms) | 1.41 | 1.45 | 1.45 |
| p95 (ms) | 1.44 | 1.48 | 1.47 |
| p98 (ms) | 1.50 | 1.78 | 1.76 |
| p99 (ms) | 3.23 | 1.84 | 1.83 |
| p100 (ms) | 15.74 | 16.48 | 16.38 |
+-----------+-----------------+------------------+--------+
For memory usage, we see a slight increase in memory usage when using Variable Width Allocation compared to master.

Average max memory usage for VWA: 147.08 MB
Average max memory usage for master: 143.49 MB
VWA uses 1.025x more memory.
jemalloc¶
For jemalloc, we see that the branch is 1.027x faster than master in RPS (standard deviation is about 3 rps). We once again see the worse p99 response times with VWA enabled.
+-----------+-----------------+------------------+--------+
| | Branch (VWA on) | Branch (VWA off) | Master |
+-----------+-----------------+------------------+--------+
| RPS | 756.06 | 741.26 | 736.31 |
| p50 (ms) | 1.30 | 1.34 | 1.34 |
| p66 (ms) | 1.32 | 1.36 | 1.37 |
| p75 (ms) | 1.33 | 1.37 | 1.39 |
| p80 (ms) | 1.34 | 1.38 | 1.39 |
| p90 (ms) | 1.36 | 1.40 | 1.41 |
| p95 (ms) | 1.38 | 1.42 | 1.44 |
| p98 (ms) | 1.42 | 1.71 | 1.70 |
| p99 (ms) | 2.74 | 1.78 | 1.78 |
| p100 (ms) | 13.42 | 16.80 | 16.45 |
+-----------+-----------------+------------------+--------+
Once again, we see a slight increase in memory usage in VWA compared to master.

Average max memory usage for VWA: 145.47 MB
Average max memory usage for master: 142.65 MB
VWA uses 1.020x more memory.
rdoc generation¶
For rdoc generation, we ran the following script for the branch and master to collect memory usage.
for x in $(seq 50)
do
sudo rm -rf .ext/rdoc; mstat -o mstat/branch_$x.tsv -freq 59 -- ruby --disable-gems "./libexec/rdoc" --root "." --encoding=UTF-8 --all --ri --op ".ext/rdoc" --page-dir "./doc" --no-force-update "."
done
For rdoc generation, we see a decrease in memory usage when using Variable Width Allocation.
glibc¶
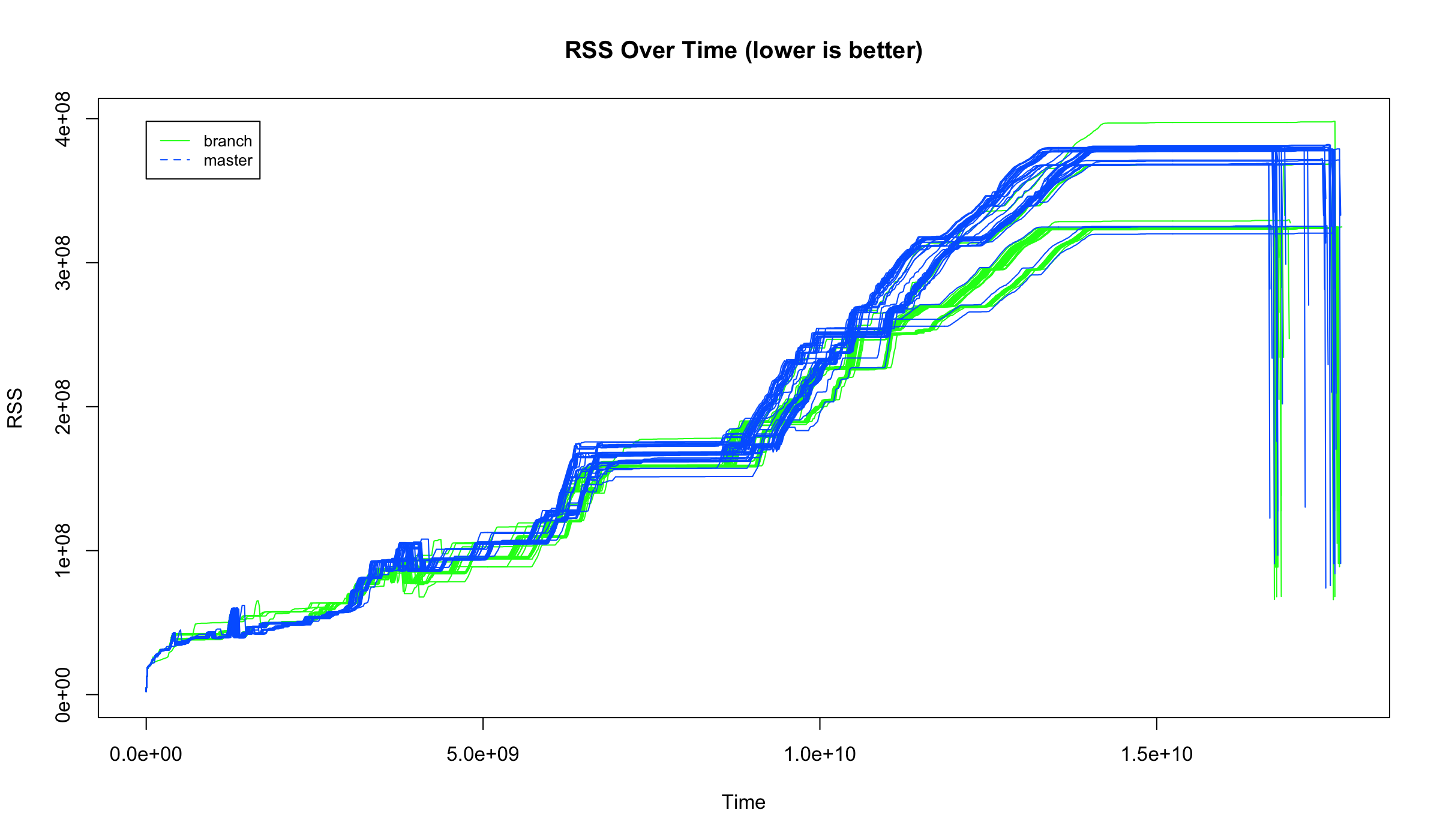
Average max memory usage for VWA: 328.83 MB
Average max memory usage for master: 373.17 MB
VWA uses 1.13x less memory.
jemalloc¶

Average max memory usage for VWA: 308.08 MB
Average max memory usage for master: 347.07 MB
VWA uses 1.13x less memory.
Liquid benchmarks¶
For the liquid benchmarks, we ran the liquid benchmark averaged over 5 runs each. We don't see any significant performance improvements or regressions here.
+----------------------+-----------------+------------------+--------+
| | Branch (VWA on) | Branch (VWA off) | Master |
+----------------------+-----------------+------------------+--------+
| Parse (i/s) | 39.60 | 39.56 | 39.45 |
| Render (i/s) | 127.69 | 126.91 | 127.06 |
| Parse & Render (i/s) | 28.42 | 28.40 | 28.30 |
+----------------------+-----------------+------------------+--------+
optcarrot¶
For optcarrot, we ran the optcarrot benchmark averaged over 5 runs each. Once again, we don't see any significant performance improvements or regressions here.
+-----+-----------------+------------------+--------+
| | Branch (VWA on) | Branch (VWA off) | Master |
+-----+-----------------+------------------+--------+
| fps | 44.54 | 45.02 | 44.15 |
+-----+-----------------+------------------+--------+
Future plans¶
- Improve within size pool compaction support. The compaction only currently compacts the first size pool (i.e. size pool with 40B slots).
- Improve ractor support. The ractor cache currently only caches the first size pool (size pool with 40B slots). Any >40B allocations require locking the VM.
- Increase coverage of Variable Width Allocation. Our next candidates are arrays and strings.
- Investigate ways to support resizing of objects within Variable Width Allocation.
- One idea is to support cross size pool compaction. So when an object requests to be resized it will be moved to the most optimal size pool.
- Use powers of 2 slot sizes in heap pages. We currently use powers of 2 multiples of RVALUE size, but it would be easier and more efficient to use powers of 2 slot sizes (i.e. 32B, 64B, 128B, etc.). However, this would mean that 24B will be wasted for objects that are 40B in size (occupy a single RVALUE) since they will be allocated into 64B slots. We believe that once more objects can take advantage of Variable Width Allocation, we will be able to shrink the size of RVALUE to 32B. As such, we only plan on investigating this once most, if not all, objects can be allocated through Variable Width Allocation.
") Updated by
Updated by ") Updated by
Updated by