Feature #11420
closed")
Introduce ID key table into MRI
Description
Let's introduce ID key table to optimization.
Background¶
Now, most of tables are implemented by st_table.
st_table is O(1) hash data structure.
MRI uses ID keys tables for many purpose like:
- method tables (mtbl) for classes/modules
- constant table for classes/modules
- attribute (index) tables for classes/modules/...
and so on.
Generally st_table is reasonable performance (speed/memory consumption), but
st_table has several drawbacks for ID key table.
- Need two words per entry for ordering (st_table_entry::olist). (memory)
- Need hash value (st_table_entry::hash). (memory)
- Need to call a function to compare IDs. (speed)
I think introducing ID key table data structure is reasonable.
Already, Yura Sokolov proposed sa_table #6962 for this purpose.
However, we can't introduce it because of several reasons.
(1) expose with st table (public API)
(2) sa_table assume ID as 32bit integer.
I need to explain (2) more. There were two reasons.
Biggest issue was Symbol GC. We planed to introduce Symbol GC.
At that time, we didn't decide we use sequential number for IDs created from dynamic symbols.
Actually, the first implementation of Symbol GC uses corresponding Symbol's object_id to represent ID.
Another issue was the available ID numbers.
ID has several fields (3 bits), so we can make 2^(32-3) IDs == 536,870,912 IDs.
We need at least (8+40)B per ID, so 536,870,912 IDs consumes 171,798,691,840 = 171GB.
It is huge, but we can't decide it is enough for future.
However, now the above issues are solved.
All IDs has sequential number from 1 (0 is reserved as undefined).
So that the current bit pattern of ID is [sequential number (64-3 or 32-3 bits)] [flags (3 bits)].
We can convert ID to [sequential number] and [sequential number] to ID.
So ID key table only keep [sequential number] as a key, instead of ID itself.
With this technique, we can keep 2^32 IDs.
Maybe it is enough because 2^32 IDs need at least 1,374,389,534,720 = 1.3TB.
(or not enough in a few years later?)
Anyway, using this technique, we can keep more IDs in 32bit integer.
Implementation¶
I want to introduce "struct rb_id_table" data structure for MRI interpreter private data structure.
id_table.h declare only common functions.
https://github.com/ko1/ruby/blob/6682a72d0f46ab3ae4c069a9e534dc0c050363f7/id_table.h
Each functions can be implemented any algorithms.
I wrote several variations.
(1) Using st (same as current implementation)
(2) Using simple array
(3) Using simple array with sequential number of ID instead of ID itself. Linear search for look up.
(4) Using simple array with sequential number of ID instead of ID itself, and sorted. Binary search for look up.
(5) Using funny falcon's Coalesced Hashing implementation [Feature #6962]
Generally, array implementation seems bad idea, but my implementation for (3), (4) uses dense array of 32bit integers, so that cache locality is nice when it is enough small table (16 entries == 64B).
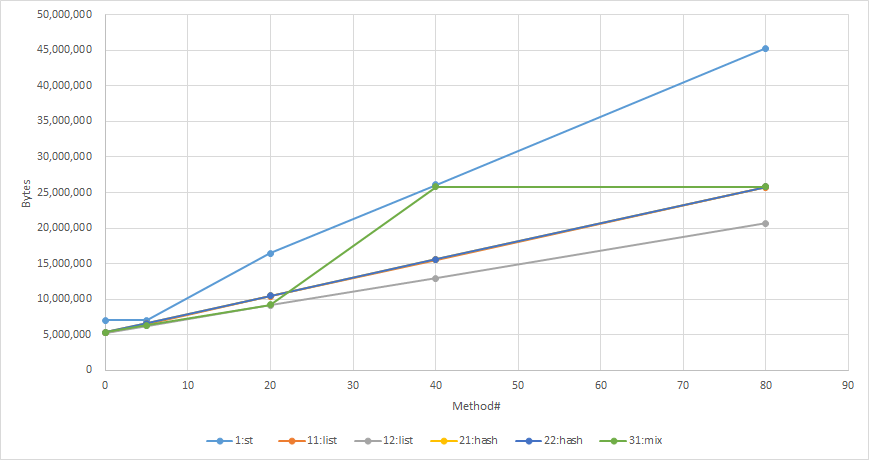
Here is a small benchmark to measure memory consumption:
require 'objspace'
def make_class method_num
Class.new{
method_num.times{|i|
define_method("m#{i}"){
}
}
}
end
C = make_class(10_000)
p ObjectSpace.memsize_of(C)
__END__
# of methods | 10K 20K
---------------------------------
(1) st : 496,560 992,944
(2) list(ID key): 262,296 524,440
(4) list(sorted): 196,760 393,368
(5) CHashing : 262,296 524,440
(Bytes)
I found that most of method tables are 0 or a few entries.
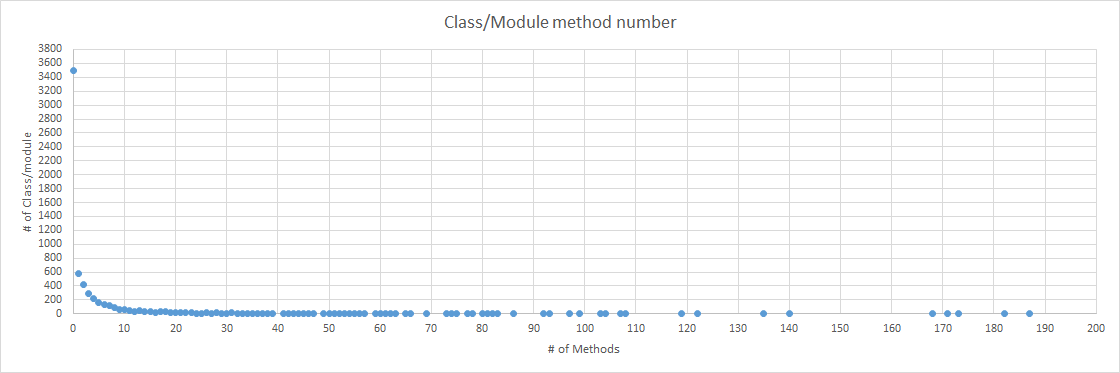
This is a survey of method number on simple rails app (development mode).
X axis shows method number and Y axis shows the number of classes/modules which have method number == X-axis.
This picture shows that 3500 classes/modules has 0 methods.
Only a few classes/modules has over 100 methods.
So combination with array (for small number of entries) and hash (for larger number of entries) will be nice.
Now I replace type of m_tbl to this struct.
See all of implementation.
https://github.com/ruby/ruby/compare/trunk...ko1:mtbl
Conclusion¶
We can compete algorithms :)
Files
") Updated by
Updated by ") Updated by
Updated by ") Updated by
Updated by ") Updated by
Updated by